Představte si, co by asi tak mohla řešit menší brněnská IT firma s americkou maminkou, která vyvíjí hodně robustní produkt na hodně konkurenčním zahraničním trhu. Kluci buší do mašin už spoustu let a dotahujou obří hráče s menšími či většími úspěchy. Přepisujou, optimalizujou, inovujou a doufají, že kápnou na něco, co přitáhne nového zákazníka nebo objeví bílý místo, které díky své rychlosti zaplní tak, že ovládnou určitý segment trhu. Tohle se totiž na tom hřišti děje, a tak vznikají kvanta řešení na určitá specifická témata.
Asi je důležitý napsat, že na tom hřišti je opravdu přeplněno - 3 mega hráči a pak 300 podobných, jako je naše firma.
Tak a teď zpátky k první větě. Já vám řeknu, co řeší - za prvé nesmí zaspat, takže sledují trendy, konkurenci a ptají se vlastních uživatelů, co ještě potřebují ke štěstí. Podle toho pak prioritizují, hledají řešení, ověřují, počítají a ve finále kódují.
No a za druhé řeší marketing a sales. Jak se dostanu k novým zákazníkům na skoro obsazeným trhu? Čím je zaujmu? Jak zjistím, že potenciální zákazník není s konkurenčním řešením spokojený? A dozvím se to včas?
Já tvrdím, že dozví – ono totiž existuje něco, co se jmenuje Developer/User group. A to je přátelé poklad. Zvlášť když máte konkurenty se skoro stejným produktem a se základnou uživatelů mnohonásobně převyšující počtem tu vaši. Bývá zvykem uživatelská fóra konkurence navštěvovat a inspirovat se při řešení nějakého specifického problému.
Naučím parazita aportovat?
Ale co kdyby existovala mašinka, která vám každý měsíc přinese nejzajímavější nápady z User group fór konkurence? Co kdyby dokázala odhalit taková témata, kterými má smysl se zabývat jak v developmentu, tak v marketingu daleko předtím, než je konkurence zařadí do vývoje? Co kdyby šlo poznatky z fór napárovat na vlastní dlouho budovanou databázi potenciálních zákazníků?
Tak s tímhle jsem do Digitální akademie vcházela – věřila jsem, že přesně takovou mašinku zvládnu udělat. No a s tímhle Digitální akademii končím. Mašinka je na světě. Zatím chroustá data jen jednoho konkurenta, ale umí přesně to, co jsem potřebovala.

Začátek všeho bylo odhalení, že Developer/User group fóra největších konkurentů jsou plná super masa a ke všemu mají v podstatě identickou strukturu. Obsahují nápady uživatelů, o kterých lze hlasovat a dostat je do vývoje, jsou zde informace o releasech, archiv starých funkcí a k tomu bohatá diskuse okolo jednotlivých návrhů. Navíc se ukázalo, že fóra dvou největších konkurentů běží na stejném řešení firmy Jive Software, což budoucí dolování dat výrazně usnadnilo.
A teď nastoupil můj mentor, aby se ve struktuře fór zorientoval a navrhl způsob získávání dat. Původně jsem si myslela, že se Pythonem prokoušu natolik, že i tuhle fázi zvládnu sama, ale nakonec jsem to vzdala. Narazila jsem na pár překážek, které jsem neuměla přeskočit a můj mentor je s C# překonal víceméně bez problémů. Pokud teda pomineme moje neustálé dotazy a dorážení, kdy už to proboha svatýho bude?! (Hodí se podotknout, že na mentora jsem sice hodně tlačila, ale zase jsem mu nabídla protiplnění v podobě chutné večeře, vypraných košil a nějakého toho dobrého slova. Mentor = můj muž😊)
A naučím ho mluvit?
Týden před odevzdáním projektu jsem tedy měla v ruce první várku dat – cca desetinu konečného objemu, abych začala dávat dohromady datový model. Vymyslela jsem si pár dodatečných požadavků, ale v zásadě byl datový set perfektní. Sestával ze třech XML souborů – User, Post a PostComment. Tabulky obsahovaly informace o uživatelích včetně uživatelských jmen založených na emailu (což se později ukázalo jako velmi užitečné), názvy a těla postů a komentů včetně informací o počtu views, votes, likes a autorů.
K těmto core tabulkám jsem scriptem přidala časovou dimenzionální tabulku, kterou nám dali k dispozici v Intelligent Technologies, kde jsem byla na stáži. Mimochodem skvělá firma s chytrými lidmi a tím nejtišším pracovním prostředím, které jsem kdy zažila.
Tady je potřeba napsat, že jsem využila na zpracování a vizualizaci dat Power BI, které jsem si hodně osahala právě na stáži a chtěla jsem v tom pokračovat, abych si fakt věřila aspoň v jednom datovém nástroji.
Základní datový model mi dal docela zabrat – celkem jsem se potrápila s časovými datovými typy. Naštěstí jsem problémy vyřešila, základní tabulky vyčistila, data anonymizovala a podařilo se mi na základě UserNames přispěvatelů ve fórech detekovat domény. Už toto samotné zjištění byl malý poklad.
Chtěla jsem se prokousat až k názvům subjektů, k čemuž jsem využila veřejně dostupný dataset se všemi potenciálními zákazníky. Bohužel měla tabulka více než 8000 řádků a Power BI začalo být hodně těžkopádné, takže jsem se rozhodla na názvy institucí rezignovat a dál jsem pracovala jen s doménami. Ty jsem využila ke spárování s databází téměř 5000 potenciálních zákazníků, se kterou firma pracuje v CRM systému Podio. To se mi nakonec podařilo, i když navázat tuto databázi nebyla malina. Nechtěla jsem pouhý export-import v csv, ale pomýšlela jsem si na živé propojení přes API. Díky automatizaci Globiflow se mi to nakonec povedlo a po mnoha mnoha transformacích jsem se propracovala až k možnosti propojit tabulky mezi sebou.
Nemusím snad ani psát, jak blažený pocit mě prostoupil, když se všechny tabulky spojily v jeden funkční celek a já jsem mohla vytvořit svůj první graf.
Datový model byl na světě, ale teď přišlo na řadu to nejvýživnější. Po několika týdnech studování informací o textové a sentiment analýze jsem s pomocí mentora prohnala těla postů a komentů přes MS Azure Cognitive services. Výsledkem bylo doplnění core tabulek o další sloupce, které obsahovaly indexy emocionálního ladění a klíčové fráze. Tato fáze byla poněkud hektická - tabulky nyní obsahují přes 2500 řádků, ale Cognitive services umí najednou analyzovat jen 1000 dokumentů a navíc mají velikostní limit na celý request, takže bylo nutné naprogramovat obecnější dotazovací algoritmus, který různorodá data předžvýká, pošle do Cognitive Services a vrácené výsledky doplní do původního zdroje dat. Taky jsme se zasekli na sentiment analýze komentů, kde byl jeden prázdný řádek a trvalo, než jsme si uvědomili, že právě na něm to drhne. Ukázalo, že při zpracování v Power BI je problém s Keywords ke každému komentu a bylo potřeba změnit logiku a napárovat je jen souhrnně na post.

V Power BI už pak byla práce jednoduchá. Je překvapivé, jak je sentiment analýza přesná. Opravdu skóre odpovídalo realitě a bylo možné na jeho základě vytvořit přehledy příspěvků s nejvyšším i nejnižším skóre, což v sobě nese ohromné možnosti pro sales i development.
Naučím!
Vím, že lidi rádi čtou jen krátké texty, což teda respektuju, ale jak už teď vidíte hodně těžko to aplikuju😊 Zvlášť, když mám ještě chuť popsat moje týdenní hraní si s daty podrobněji.
Jaké objevy jsem uskutečnila, aby mě pak přemohlo zklamání, že jsem metriku nastavila špatně. Jak jsem přišla na spoustu nedokonalostí zdrojových dat, a tak jsem je čistila a čistila. Jak jsem se zasekávala na neřešitelných problémech a myslela si o sobě, že jsem fakt totálně tupá. A jak jsem je následně vyřešila a měla radost, že mi to fakt pálí. Jak jsem prokrastinovala vylepšováním grafické podoby vizualizací. Jak jsem dostala nový data set od muže, který obsahoval díky stránkování duplicity, kterých jsem se neuměla zbavit a problémy vždycky zjistila až po 20 minutách, kdy se data do Power BI načítala. Shrnuto a podtrženo je to tak 80:20 - 80% času na práci byla frustrace a 20% veliká radost, když z toho všeho lezly opravdu zajímavé praktické informace.
Výsledkem toho všeho bylo:
Kdyby vás zajímalo, jak to ve finále vypadá, tak tady je pár obrazovek.
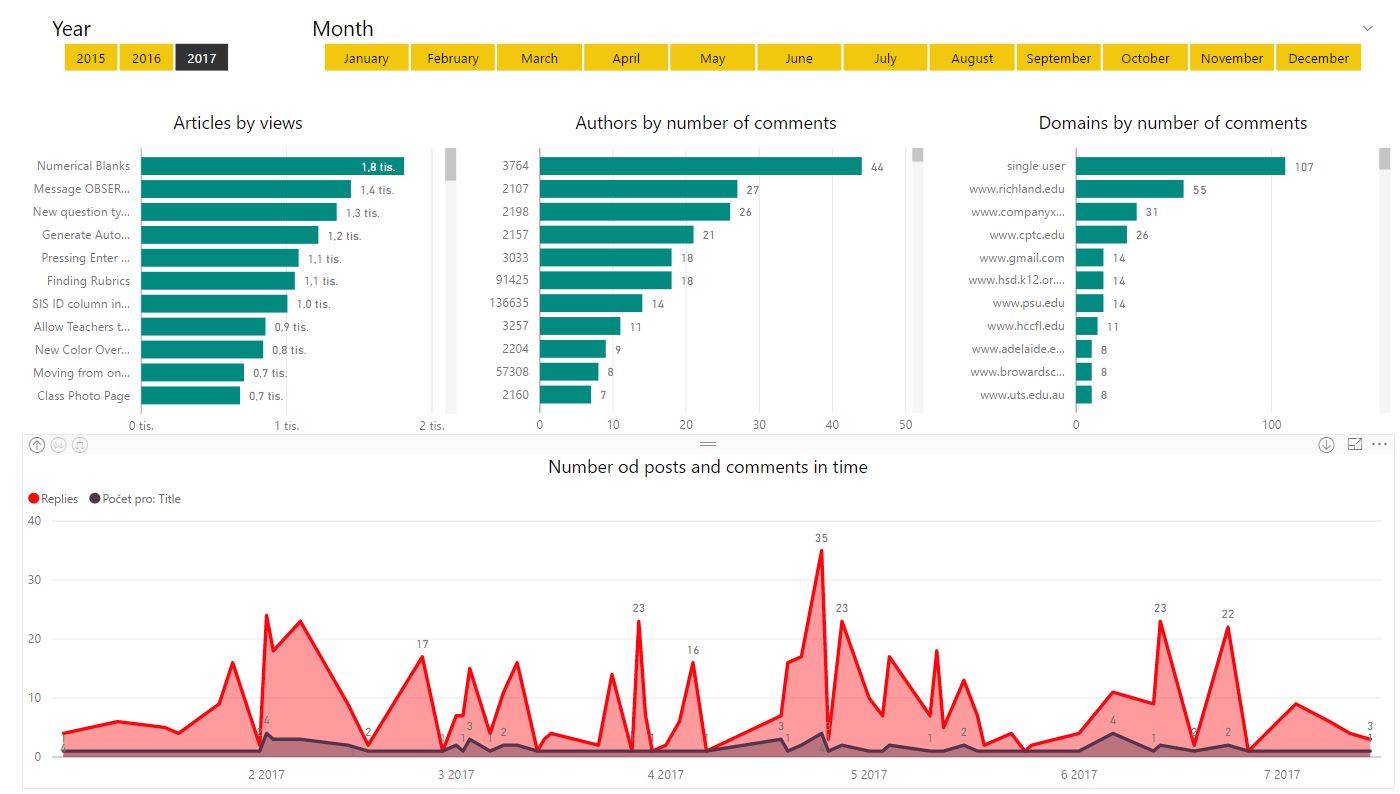
Obecný přehled v čase:







Asi je důležitý napsat, že na tom hřišti je opravdu přeplněno - 3 mega hráči a pak 300 podobných, jako je naše firma.
Tak a teď zpátky k první větě. Já vám řeknu, co řeší - za prvé nesmí zaspat, takže sledují trendy, konkurenci a ptají se vlastních uživatelů, co ještě potřebují ke štěstí. Podle toho pak prioritizují, hledají řešení, ověřují, počítají a ve finále kódují.
No a za druhé řeší marketing a sales. Jak se dostanu k novým zákazníkům na skoro obsazeným trhu? Čím je zaujmu? Jak zjistím, že potenciální zákazník není s konkurenčním řešením spokojený? A dozvím se to včas?
Já tvrdím, že dozví – ono totiž existuje něco, co se jmenuje Developer/User group. A to je přátelé poklad. Zvlášť když máte konkurenty se skoro stejným produktem a se základnou uživatelů mnohonásobně převyšující počtem tu vaši. Bývá zvykem uživatelská fóra konkurence navštěvovat a inspirovat se při řešení nějakého specifického problému.
Naučím parazita aportovat?
Ale co kdyby existovala mašinka, která vám každý měsíc přinese nejzajímavější nápady z User group fór konkurence? Co kdyby dokázala odhalit taková témata, kterými má smysl se zabývat jak v developmentu, tak v marketingu daleko předtím, než je konkurence zařadí do vývoje? Co kdyby šlo poznatky z fór napárovat na vlastní dlouho budovanou databázi potenciálních zákazníků?
Tak s tímhle jsem do Digitální akademie vcházela – věřila jsem, že přesně takovou mašinku zvládnu udělat. No a s tímhle Digitální akademii končím. Mašinka je na světě. Zatím chroustá data jen jednoho konkurenta, ale umí přesně to, co jsem potřebovala.
{kind=link}
Začátek všeho bylo odhalení, že Developer/User group fóra největších konkurentů jsou plná super masa a ke všemu mají v podstatě identickou strukturu. Obsahují nápady uživatelů, o kterých lze hlasovat a dostat je do vývoje, jsou zde informace o releasech, archiv starých funkcí a k tomu bohatá diskuse okolo jednotlivých návrhů. Navíc se ukázalo, že fóra dvou největších konkurentů běží na stejném řešení firmy Jive Software, což budoucí dolování dat výrazně usnadnilo.
A teď nastoupil můj mentor, aby se ve struktuře fór zorientoval a navrhl způsob získávání dat. Původně jsem si myslela, že se Pythonem prokoušu natolik, že i tuhle fázi zvládnu sama, ale nakonec jsem to vzdala. Narazila jsem na pár překážek, které jsem neuměla přeskočit a můj mentor je s C# překonal víceméně bez problémů. Pokud teda pomineme moje neustálé dotazy a dorážení, kdy už to proboha svatýho bude?! (Hodí se podotknout, že na mentora jsem sice hodně tlačila, ale zase jsem mu nabídla protiplnění v podobě chutné večeře, vypraných košil a nějakého toho dobrého slova. Mentor = můj muž😊)
A naučím ho mluvit?
Týden před odevzdáním projektu jsem tedy měla v ruce první várku dat – cca desetinu konečného objemu, abych začala dávat dohromady datový model. Vymyslela jsem si pár dodatečných požadavků, ale v zásadě byl datový set perfektní. Sestával ze třech XML souborů – User, Post a PostComment. Tabulky obsahovaly informace o uživatelích včetně uživatelských jmen založených na emailu (což se později ukázalo jako velmi užitečné), názvy a těla postů a komentů včetně informací o počtu views, votes, likes a autorů.
K těmto core tabulkám jsem scriptem přidala časovou dimenzionální tabulku, kterou nám dali k dispozici v Intelligent Technologies, kde jsem byla na stáži. Mimochodem skvělá firma s chytrými lidmi a tím nejtišším pracovním prostředím, které jsem kdy zažila.
Tady je potřeba napsat, že jsem využila na zpracování a vizualizaci dat Power BI, které jsem si hodně osahala právě na stáži a chtěla jsem v tom pokračovat, abych si fakt věřila aspoň v jednom datovém nástroji.
Základní datový model mi dal docela zabrat – celkem jsem se potrápila s časovými datovými typy. Naštěstí jsem problémy vyřešila, základní tabulky vyčistila, data anonymizovala a podařilo se mi na základě UserNames přispěvatelů ve fórech detekovat domény. Už toto samotné zjištění byl malý poklad.
Chtěla jsem se prokousat až k názvům subjektů, k čemuž jsem využila veřejně dostupný dataset se všemi potenciálními zákazníky. Bohužel měla tabulka více než 8000 řádků a Power BI začalo být hodně těžkopádné, takže jsem se rozhodla na názvy institucí rezignovat a dál jsem pracovala jen s doménami. Ty jsem využila ke spárování s databází téměř 5000 potenciálních zákazníků, se kterou firma pracuje v CRM systému Podio. To se mi nakonec podařilo, i když navázat tuto databázi nebyla malina. Nechtěla jsem pouhý export-import v csv, ale pomýšlela jsem si na živé propojení přes API. Díky automatizaci Globiflow se mi to nakonec povedlo a po mnoha mnoha transformacích jsem se propracovala až k možnosti propojit tabulky mezi sebou.
Nemusím snad ani psát, jak blažený pocit mě prostoupil, když se všechny tabulky spojily v jeden funkční celek a já jsem mohla vytvořit svůj první graf.
Datový model byl na světě, ale teď přišlo na řadu to nejvýživnější. Po několika týdnech studování informací o textové a sentiment analýze jsem s pomocí mentora prohnala těla postů a komentů přes MS Azure Cognitive services. Výsledkem bylo doplnění core tabulek o další sloupce, které obsahovaly indexy emocionálního ladění a klíčové fráze. Tato fáze byla poněkud hektická - tabulky nyní obsahují přes 2500 řádků, ale Cognitive services umí najednou analyzovat jen 1000 dokumentů a navíc mají velikostní limit na celý request, takže bylo nutné naprogramovat obecnější dotazovací algoritmus, který různorodá data předžvýká, pošle do Cognitive Services a vrácené výsledky doplní do původního zdroje dat. Taky jsme se zasekli na sentiment analýze komentů, kde byl jeden prázdný řádek a trvalo, než jsme si uvědomili, že právě na něm to drhne. Ukázalo, že při zpracování v Power BI je problém s Keywords ke každému komentu a bylo potřeba změnit logiku a napárovat je jen souhrnně na post.

V Power BI už pak byla práce jednoduchá. Je překvapivé, jak je sentiment analýza přesná. Opravdu skóre odpovídalo realitě a bylo možné na jeho základě vytvořit přehledy příspěvků s nejvyšším i nejnižším skóre, což v sobě nese ohromné možnosti pro sales i development.
Naučím!
Vím, že lidi rádi čtou jen krátké texty, což teda respektuju, ale jak už teď vidíte hodně těžko to aplikuju😊 Zvlášť, když mám ještě chuť popsat moje týdenní hraní si s daty podrobněji.
Jaké objevy jsem uskutečnila, aby mě pak přemohlo zklamání, že jsem metriku nastavila špatně. Jak jsem přišla na spoustu nedokonalostí zdrojových dat, a tak jsem je čistila a čistila. Jak jsem se zasekávala na neřešitelných problémech a myslela si o sobě, že jsem fakt totálně tupá. A jak jsem je následně vyřešila a měla radost, že mi to fakt pálí. Jak jsem prokrastinovala vylepšováním grafické podoby vizualizací. Jak jsem dostala nový data set od muže, který obsahoval díky stránkování duplicity, kterých jsem se neuměla zbavit a problémy vždycky zjistila až po 20 minutách, kdy se data do Power BI načítala. Shrnuto a podtrženo je to tak 80:20 - 80% času na práci byla frustrace a 20% veliká radost, když z toho všeho lezly opravdu zajímavé praktické informace.
Výsledkem toho všeho bylo:
- odhalení hot topics ve fórech konkurence
- nastavení strange indexu, který dokáže detekovat příspěvky, které jsou nějakým způsobem nestandartní (například hodně views, málo votes a nízké sentiment skóre)
- zjištění zájmu konkurenta dle jeho převládající aktivity v některých vláknech
- nespokojenost uživatelů s produktem konkurenta a spárování instituce s firemním CRM záznamem
- schopnost vyhledávat dle instituce z CRM a zjišťovat jejich zájem a klíčové oblasti
- sebepoznání, že ani po třech dětech nejsem dostatečně trpělivá
- a že nemám muže lákat na novou vizualizaci v brzkých ranních hodinách
Kdyby vás zajímalo, jak to ve finále vypadá, tak tady je pár obrazovek.
Obecný přehled v čase:

{kind=link}
Analýza zájmu konkurenta s možností projít konkrétní post:

{kind=link}
Sentiment analýza a napárování na databázi potenciálních zákazníků firmy:

{kind=link}
Výpis příspěvků a keywords na základě sentiment skóre:

{kind=link}
Strange index a párování s potenciálními zákazníky:

{kind=link}
Parazit chce kamaráda
Teprve nedávno jsem se o sobě dozvěděla, že jsem multipotenciál (vysvětlení zde) a přestala jsem se stydět za svůj hodně široký záběr. Mám naprosto nezvladatelnou touhu propojovat obory, hledat synergie při řešení problémů, spojovat lidi a hlavně vytvářet komplexní řešení.
S tímto nastavením jsem nemohla jinak - pro presales organizace mi ještě chyběla analýza webu firmy, a tak jsem k projektu parazita user fór přifařila ještě nadstavbu v podobě analýzy Google Analytics a napárování opět na CRM společnosti. Tady jsem si zkusila přenos datového modelu, protože jsem to rovnou zkoušela na dvou GA účtech.
Zjistila jsem, že API Google Analytics je s prominutím pakárna, protože mi nedovolí některé operace, které se mi jeví jako základní a že když si nedáte pozor, tak vás čeština v Power BI položí na lopatky. Nakonec jsem ale s výsledkem tak nějak spokojená a plánuju k tomu pro úplnost ještě přidat Twitter feed.
Obecný přehled s napárováním na databázi potenciálních zákazníků:

Srovnání výkonnosti webu v čase:

Tak a příště akrobacii!
A co teď dál? Ono to má dvě roviny - první se týká samotné závěrečné práce a ta druhá mého pracovního já.
Závěrečnou práci bych ráda ještě dopracovala, aby ji firma opravdu využila pro prioritizaci leads. K tomu by bylo dobré:
- zmapovat i další oblasti fór (releases, in development, archiv)
- zařadit více konkurentů a vlastní suggestions
- domakat textovou a sentiment analýzu k dokonalosti
- odhalit délku vývoje konkurentů a jejich priority
- zpřesnit strange index a detekovat oblasti, které budou maximálně zajímavé pro vývoj našeho produktu
- vytvořit SQL databázi a udělat přímou propojku na data
- vyřešit problém s limitem vycucávaných dat
- najít nebo vytvořit novou mašinku, která si poradí pružněji s velkými datovými tabulkami
- přidat zdroje dat, které budou obsahovat informace o výběrových řízeních
- přidat zdroje dat o všech potenciálních zákaznících a prioritizovat vývoj i sales i na základě dat, která nejsou spjata přímo s fóry
- umět vyhledávat a číst trendové články a blogy a vytvářet nad nimi textové a sentiment analýzy
- napojit i zdroje z Google Analytics a sociálních sítí
- celé to zabalit, přidat notifikace, zpětný přenos dat do CRM, krásné reporty a zkusit to nabídnout jako produkt nějaké jiné firmě, kde je produkťák, co má rád mapu bez bílých míst
- to čtení fór a sociálních sítí má obecně dost slušný potenciál – třeba by se mohly poznatky z nich využívat v remarketingu, protože právě v nich probíhá často rozhodování o nákupu
Ta druhá rovina je osobní/a tady bych do budoucna fakt chtěla:
- dál pracovat s daty a prokousat se dalšími technologiemi
- kápnout na komplexní dlouhodobé projekty, které uchopím od A do Z (ono mě nejvíc baví hledat ty správné otázky, a na to já potřebuju širokou cestu)
- dát dohromady tým, který netvořím jen já a můj zotročený muž
- vybudovat si silné portfolio, zlepšit svoji sebeprezentaci a odměnu za svoji práci posunout na vyšší level
- najít si práci či zakázky, které půjdou skloubit s mojí rodinou
Jak na cvičišti, tak na bojišti
Digitální akademie končí a já jsem moc ráda, že jsem měla možnost se jí zúčastnit. I přes menší zádrhele jsem se posunula dál, otevřela jsem black box programování a překvapila sama sebe, jak mě to bavilo. Zároveň vím, že moje síla je někde jinde. Jinými slovy - programovat asi nebudu, ale jsem opravdu moc ráda, že chápu základní principy.
Ona má datová analýza spoustu vrstev a mě baví právě ta detektivní. Asi by bylo drzé říkat si data analytik, ale můžu si říkat data detektiv? Koukat se, hledat otázky a cesty, jak je zodpovědět - tam se do budoucna vidím, ať už mě vítr zavane do jakéhokoliv oboru.
Mimoto jsem si díky Digitální akademii ověřila, že mám fakt báječnou rodinu, která mi maximálně vyšla vstříc. A že se v Czechitas koncentrujou naprosto skvělý, inspirativní a chytrý ženský.
Mimochodem možnost zpracovat závěrečný projekt jako blog post je skvělý nápad, ale uvědomil si někdo, že existují i kecálisti jako jsem já?;-)
Je to epické Veru a jsem moc ráda, že nejsem jediná, kdo zvolil trošku neformálnější styl zápisu. :-)
OdpovědětVymazat